
18. 함수 (2) - 스코프와 고급 기능
함수 안에서 만든 변수는 밖에서 쓸 수 없다? 인자를 몇 개든 받을 수 있는 함수? 한 줄짜리 함수? 함수의 심화 기능을 익히면 코드가 한 단계 더 유연해진다.
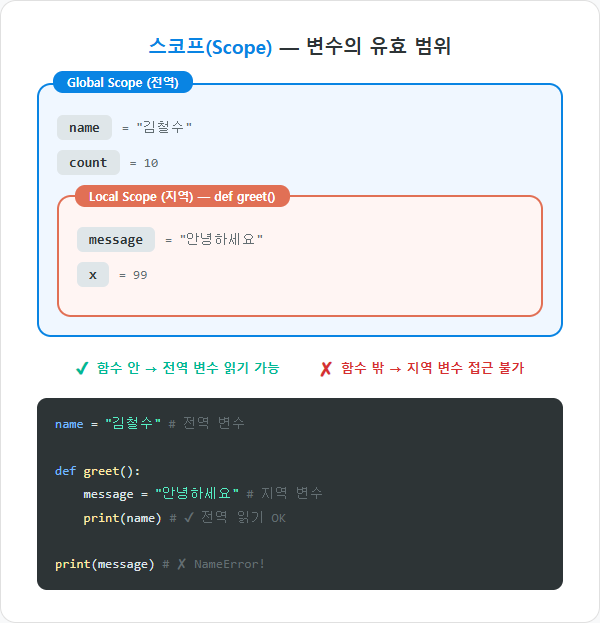
변수의 스코프 (Scope)
스코프란 변수가 살아있는 범위다. 파이썬에서 변수는 어디서 만들었느냐에 따라 접근 가능한 범위가 달라진다.
지역 변수 (Local Variable)
함수 안에서 만든 변수는 함수 안에서만 사용할 수 있다.
def greet():
message = "안녕하세요" # 지역 변수
print(message)
greet() # 안녕하세요
print(message) # NameError! 함수 밖에서 접근 불가전역 변수 (Global Variable)
함수 밖에서 만든 변수는 어디서든 읽을 수 있다.
name = "김철수" # 전역 변수
def greet():
print(f"안녕하세요, {name}님!") # 전역 변수 읽기 가능
greet() # 안녕하세요, 김철수님!
print(name) # 김철수같은 이름의 변수
함수 안에서 같은 이름의 변수를 만들면, 지역 변수가 우선된다.
x = 10 # 전역 변수
def test():
x = 99 # 지역 변수 (전역 x와 별개)
print(f"함수 안: {x}")
test() # 함수 안: 99
print(f"함수 밖: {x}") # 함수 밖: 10 (전역 x는 그대로)
global 키워드
함수 안에서 전역 변수를 수정하려면 global 키워드를 사용한다.
count = 0
def increment():
global count # 전역 변수 count를 수정하겠다고 선언
count += 1
increment()
increment()
increment()
print(count) # 3⚠️ 주의:
global은 가급적 사용하지 않는 것이 좋다. 함수는 매개변수와 return으로 데이터를 주고받는 것이 깔끔하다.
# global 대신 이렇게!
def increment(count):
return count + 1
count = 0
count = increment(count) # 1
count = increment(count) # 2LEGB 규칙
파이썬은 변수를 찾을 때 LEGB 순서로 탐색한다.
L (Local) → 함수 내부
E (Enclosing) → 감싸는 함수 (중첩 함수일 때)
G (Global) → 모듈(파일) 전체
B (Built-in) → 파이썬 내장x = "전역" # Global
def outer():
x = "외부함수" # Enclosing
def inner():
x = "내부함수" # Local
print(x)
inner()
outer() # 내부함수*args - 가변 위치 인자
매개변수 이름 앞에 *를 붙이면, 여러 개의 인자를 튜플로 받을 수 있다.
def add_all(*args):
print(f"받은 인자: {args}") # 튜플로 저장됨
return sum(args)
print(add_all(1, 2, 3)) # 받은 인자: (1, 2, 3) → 6
print(add_all(10, 20, 30, 40)) # 받은 인자: (10, 20, 30, 40) → 100
print(add_all(5)) # 받은 인자: (5,) → 5일반 매개변수와 함께 사용
def introduce(name, *hobbies):
print(f"이름: {name}")
print(f"취미: {', '.join(hobbies)}")
introduce("김철수", "독서", "게임", "요리")
# 이름: 김철수
# 취미: 독서, 게임, 요리**kwargs - 가변 키워드 인자
매개변수 이름 앞에 **를 붙이면, 키워드 인자를 딕셔너리로 받을 수 있다.
def print_info(**kwargs):
print(f"받은 인자: {kwargs}") # 딕셔너리로 저장됨
for key, value in kwargs.items():
print(f" {key}: {value}")
print_info(name="김철수", age=25, city="서울")
# 받은 인자: {'name': '김철수', 'age': 25, 'city': '서울'}
# name: 김철수
# age: 25
# city: 서울args와 *kwargs 함께 사용
def flex_func(*args, **kwargs):
print(f"위치 인자: {args}")
print(f"키워드 인자: {kwargs}")
flex_func(1, 2, 3, name="철수", age=25)
# 위치 인자: (1, 2, 3)
# 키워드 인자: {'name': '철수', 'age': 25}💡 순서 규칙:
일반 매개변수→*args→키워드 매개변수→**kwargs
def example(a, b, *args, option=True, **kwargs):
print(a, b, args, option, kwargs)
example(1, 2, 3, 4, option=False, x=10)
# 1 2 (3, 4) False {'x': 10}

람다 함수 (lambda)
lambda는 이름 없는 한 줄 함수다. 간단한 함수를 빠르게 만들 때 사용한다.
# 일반 함수
def square(x):
return x ** 2
# 람다 함수 (같은 기능)
square = lambda x: x ** 2
print(square(5)) # 25문법
lambda 매개변수: 표현식# 두 수의 합
add = lambda a, b: a + b
print(add(3, 5)) # 8
# 짝수 판별
is_even = lambda x: x % 2 == 0
print(is_even(4)) # True
print(is_even(7)) # False
# 조건 표현식과 함께
grade = lambda score: "합격" if score >= 60 else "불합격"
print(grade(85)) # 합격
print(grade(45)) # 불합격💡 람다는 한 줄 표현식만 가능하다. 복잡한 로직은 일반 함수로 작성하자.
map() 함수
map(함수, 반복가능객체) — 모든 요소에 함수를 적용한 결과를 반환한다.
numbers = [1, 2, 3, 4, 5]
# 일반적인 방법
squared = []
for n in numbers:
squared.append(n ** 2)
print(squared) # [1, 4, 9, 16, 25]
# map 사용
squared = list(map(lambda x: x ** 2, numbers))
print(squared) # [1, 4, 9, 16, 25]# 문자열 리스트를 정수로 변환
str_nums = ["10", "20", "30"]
int_nums = list(map(int, str_nums))
print(int_nums) # [10, 20, 30]
# 이름에 "님" 붙이기
names = ["김철수", "이영희", "박민수"]
result = list(map(lambda name: name + "님", names))
print(result) # ['김철수님', '이영희님', '박민수님']filter() 함수
filter(함수, 반복가능객체) — 함수가 True를 반환하는 요소만 걸러낸다.
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 짝수만 필터링
evens = list(filter(lambda x: x % 2 == 0, numbers))
print(evens) # [2, 4, 6, 8, 10]
# 80점 이상만 필터링
scores = [65, 92, 78, 88, 55, 95, 42]
passed = list(filter(lambda s: s >= 80, scores))
print(passed) # [92, 88, 95]map과 filter 조합
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 짝수만 골라서 제곱
result = list(map(lambda x: x ** 2, filter(lambda x: x % 2 == 0, numbers)))
print(result) # [4, 16, 36, 64, 100]
# 리스트 컴프리헨션으로 같은 결과 (더 읽기 쉬움)
result = [x ** 2 for x in numbers if x % 2 == 0]
print(result) # [4, 16, 36, 64, 100]sorted()와 lambda
sorted()의 key 매개변수에 람다를 사용하면 정렬 기준을 자유롭게 설정할 수 있다.
# 절대값 기준 정렬
numbers = [-5, 3, -1, 4, -2]
result = sorted(numbers, key=lambda x: abs(x))
print(result) # [-1, -2, 3, 4, -5]
# 문자열 길이 기준 정렬
words = ["banana", "apple", "cherry", "date"]
result = sorted(words, key=lambda w: len(w))
print(result) # ['date', 'apple', 'banana', 'cherry']
# 딕셔너리 리스트를 특정 키로 정렬
students = [
{"name": "김철수", "score": 85},
{"name": "이영희", "score": 92},
{"name": "박민수", "score": 78},
]
result = sorted(students, key=lambda s: s["score"], reverse=True)
for s in result:
print(f"{s['name']}: {s['score']}점")
# 이영희: 92점
# 김철수: 85점
# 박민수: 78점실전 예시: 학생 데이터 처리
students = [
{"name": "김철수", "scores": [85, 90, 78]},
{"name": "이영희", "scores": [92, 88, 95]},
{"name": "박민수", "scores": [70, 65, 80]},
{"name": "최지원", "scores": [88, 92, 90]},
]
def get_average(*scores):
"""여러 점수의 평균 계산"""
return sum(scores) / len(scores)
def process_students(students, min_avg=80):
"""학생 데이터 처리: 평균 계산 + 합격자 필터링"""
# 평균 추가
for s in students:
s["avg"] = get_average(*s["scores"])
# 합격자 필터링
passed = list(filter(lambda s: s["avg"] >= min_avg, students))
# 평균 높은 순 정렬
passed.sort(key=lambda s: s["avg"], reverse=True)
return passed
result = process_students(students)
for s in result:
print(f"{s['name']}: 평균 {s['avg']:.1f}점")
# 이영희: 평균 91.7점
# 최지원: 평균 90.0점
# 김철수: 평균 84.3점직접 해보기
문제 1. 전역 변수 total을 0으로 초기화하고, 숫자 리스트를 받아 total에 합계를 누적하는 add_to_total(numbers) 함수를 만들어보자.
문제 2. *args를 사용해서 받은 모든 숫자 중 최대값과 최소값을 튜플로 반환하는 min_max(*args) 함수를 만들어보자.
문제 3. **kwargs를 사용해서 학생 정보를 "키: 값" 형태로 출력하는 print_student(**kwargs) 함수를 만들어보자.
문제 4. map()과 lambda를 사용해서 리스트 [1, 2, 3, 4, 5]의 각 요소를 세제곱한 리스트를 만들어보자.
문제 5. filter()와 lambda를 사용해서 문자열 리스트에서 길이가 3 이하인 것만 걸러내보자.
정답 보기
# 문제 1
total = 0
def add_to_total(numbers):
global total
total += sum(numbers)
add_to_total([10, 20, 30])
add_to_total([5, 15])
print(total) # 80
# 문제 2
def min_max(*args):
return min(args), max(args)
print(min_max(3, 7, 1, 9, 2)) # (1, 9)
print(min_max(100, 50)) # (50, 100)
# 문제 3
def print_student(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
print_student(이름="김철수", 나이=20, 학과="컴퓨터공학")
# 이름: 김철수
# 나이: 20
# 학과: 컴퓨터공학
# 문제 4
cubed = list(map(lambda x: x ** 3, [1, 2, 3, 4, 5]))
print(cubed) # [1, 8, 27, 64, 125]
# 문제 5
words = ["hi", "hello", "yes", "no", "python", "ok"]
short = list(filter(lambda w: len(w) <= 3, words))
print(short) # ['hi', 'yes', 'no', 'ok']오늘의 정리
| 항목 | 내용 |
|---|---|
| 지역 변수 | 함수 안에서 만든 변수. 함수 밖에서 접근 불가 |
| 전역 변수 | 함수 밖에서 만든 변수. 어디서든 읽기 가능 |
| global | 함수 안에서 전역 변수를 수정할 때 사용 |
| *args | 여러 위치 인자를 튜플로 받음 |
| **kwargs | 여러 키워드 인자를 딕셔너리로 받음 |
| lambda | lambda 매개변수: 표현식 — 한 줄 익명 함수 |
| map() | 모든 요소에 함수 적용. list(map(함수, 리스트)) |
| filter() | 조건에 맞는 요소만 걸러냄. list(filter(함수, 리스트)) |
다음 편 예고: 재귀 함수 - 자기 자신을 호출하는 함수
함수가 자기 자신을 호출한다고? 팩토리얼, 피보나치 수열, 하노이 탑까지 — 재귀 함수의 마법 같은 세계를 탐험해보자.
태그: 파이썬 Python 파이썬독학 함수 스코프 args kwargs 람다함수 lambda 파이썬기초 IT교육
'Python' 카테고리의 다른 글
| 20. 데코레이터와 제너레이터 - 중급으로 가는 관문 (1) | 2026.02.22 |
|---|---|
| 19. 재귀 함수 - 자기 자신을 호출하는 함수 (0) | 2026.02.22 |
| 17. 함수 (1) - 코드를 재사용하는 방법 (0) | 2026.02.22 |
| 16. 자료구조 비교 총정리 - 상황별 선택 가이드 (0) | 2026.02.22 |
| 15. 컴프리헨션 - 파이썬다운 코드 작성법 (0) | 2026.02.22 |




댓글