반응형

16. 자료구조 비교 총정리 - 상황별 선택 가이드
리스트, 튜플, 세트, 딕셔너리. 네 가지를 모두 배웠는데, 실전에서 뭘 써야 할지 아직 고민된다면? 이 글 하나로 상황별 최적의 선택을 내릴 수 있게 되자.
한눈에 비교
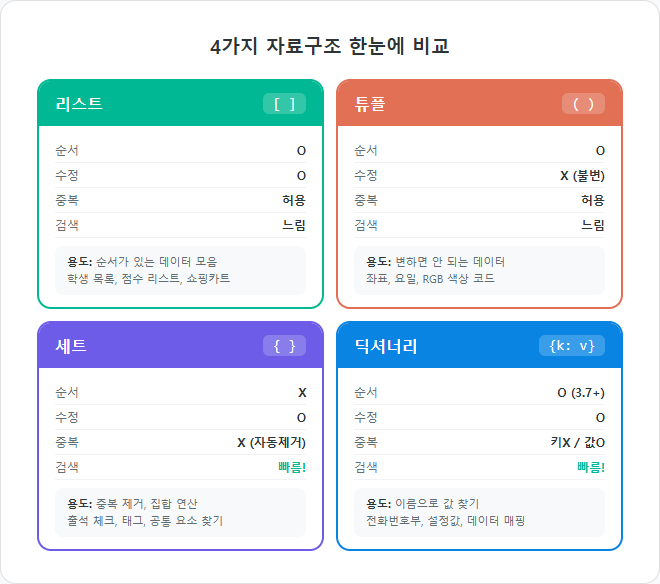
| 특성 | 리스트 [ ] | 튜플 ( ) | 세트 { } | 딕셔너리 {k:v} |
|---|---|---|---|---|
| 순서 | O | O | X | O (3.7+) |
| 수정 가능 | O | X | O | O |
| 중복 허용 | O | O | X | 키X / 값O |
| 인덱싱 | O | O | X | 키로 접근 |
| 생성 방법 | [1, 2, 3] | (1, 2, 3) | {1, 2, 3} | {"a": 1} |
상황별 선택 가이드
"어떤 자료구조를 써야 할까?" 판단 흐름
1. 키-값 쌍이 필요하다 → 딕셔너리
2. 중복 제거가 필요하다 → 세트
3. 데이터가 바뀌면 안 된다 → 튜플
4. 그 외 → 리스트상황별 예시
| 상황 | 추천 | 이유 |
|---|---|---|
| 학생 점수 목록 | 리스트 | 순서 있고, 추가/삭제 필요 |
| 이름으로 점수 찾기 | 딕셔너리 | 키(이름)로 값(점수) 매핑 |
| 요일 (월~일) | 튜플 | 변하지 않는 고정 데이터 |
| 출석한 학생 (중복 없이) | 세트 | 중복 자동 제거, 집합 연산 |
| 쇼핑카트 상품 목록 | 리스트 | 같은 상품 여러 개 가능, 순서 필요 |
| 좌표 (x, y) | 튜플 | 좌표는 변하면 안 됨 |
| 설정 값 (이름: 값) | 딕셔너리 | 설정 이름으로 값에 접근 |
| 태그/카테고리 (고유) | 세트 | 중복 없는 고유 값의 모음 |
검색 속도 비교
"이 값이 있는가?" 확인(in 연산)의 속도 차이는 데이터가 많아질수록 크다.
# 리스트: 처음부터 끝까지 하나씩 확인 (느림)
5 in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # 5번째에서 발견
# 세트/딕셔너리: 해시 기반으로 즉시 찾음 (빠름)
5 in {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} # 바로 발견| 연산 | 리스트 | 튜플 | 세트 | 딕셔너리 |
|---|---|---|---|---|
| x in 검색 | 느림 | 느림 | 빠름 | 빠름 |
| 인덱스 접근 | 빠름 | 빠름 | 불가 | 빠름 (키) |
| 추가 | 빠름 (끝) | 불가 | 빠름 | 빠름 |
💡 실전 팁: "이 값이 포함되어 있는가?"를 자주 확인해야 한다면, 리스트 대신 세트나 딕셔너리를 사용하면 훨씬 빠르다.
# 느린 방법
banned_list = ["spam", "ad", "fake"] # 리스트
if word in banned_list: ... # 하나씩 비교
# 빠른 방법
banned_set = {"spam", "ad", "fake"} # 세트
if word in banned_set: ... # 즉시 확인자료구조 간 변환
# 리스트 ↔ 튜플
my_list = [1, 2, 3]
my_tuple = tuple(my_list) # (1, 2, 3)
back_list = list(my_tuple) # [1, 2, 3]
# 리스트 → 세트 (중복 제거)
data = [1, 2, 2, 3, 3, 3]
unique = set(data) # {1, 2, 3}
unique_list = list(unique) # [1, 2, 3]
# 리스트 → 딕셔너리 (zip 활용)
keys = ["name", "age", "city"]
values = ["김철수", 25, "서울"]
info = dict(zip(keys, values)) # {'name': '김철수', 'age': 25, 'city': '서울'}
# 딕셔너리 → 리스트
person = {"name": "김철수", "age": 25}
key_list = list(person.keys()) # ['name', 'age']
value_list = list(person.values()) # ['김철수', 25]실전 예시: 텍스트 분석기
네 가지 자료구조를 모두 활용하는 종합 예제다.
text = """파이썬은 배우기 쉽다 파이썬은 강력하다
파이썬으로 웹개발도 가능하다 파이썬으로 데이터분석도 가능하다
파이썬은 인기있는 언어다"""
# 1. 리스트: 단어 분리
words = text.split()
print(f"총 단어 수: {len(words)}")
# 2. 세트: 고유 단어
unique_words = set(words)
print(f"고유 단어 수: {len(unique_words)}")
# 3. 딕셔너리: 단어 빈도수
word_count = {}
for word in words:
word_count[word] = word_count.get(word, 0) + 1
# 빈도순 정렬
sorted_words = sorted(word_count.items(), key=lambda x: x[1], reverse=True)
print("\n단어 빈도수 (상위 5개):")
for word, count in sorted_words[:5]:
bar = "█" * count
print(f" {word:10s} {bar} ({count}회)")
# 4. 튜플: 결과를 변경 불가능하게 저장
result = tuple(sorted_words[:3])
print(f"\n상위 3개 (변경 불가): {result}")직접 해보기
문제 1. 학생 데이터를 적절한 자료구조로 관리해보자.
5명의 학생 이름과 점수를 저장하고:
- 전체 평균 구하기
- 최고 점수 학생 찾기
- 80점 이상 학생만 추출문제 2. 두 반의 학생 출석 데이터를 세트로 처리해보자.
class_a = {"김철수", "이영희", "박민수", "최지원", "정다은"}
class_b = {"이영희", "박민수", "한미경", "오준서", "정다은"}
# 구하기: 두 반 모두 출석한 학생, A반에만 있는 학생정답 보기
# 문제 1
students = {"김철수": 85, "이영희": 92, "박민수": 78, "최지원": 95, "정다은": 68}
# 전체 평균
avg = sum(students.values()) / len(students)
print(f"평균: {avg:.1f}")
# 최고 점수
top = max(students, key=students.get)
print(f"1등: {top} ({students[top]}점)")
# 80점 이상
passed = {name: score for name, score in students.items() if score >= 80}
print(f"80점 이상: {passed}")
# 문제 2
class_a = {"김철수", "이영희", "박민수", "최지원", "정다은"}
class_b = {"이영희", "박민수", "한미경", "오준서", "정다은"}
both = class_a & class_b
print(f"두 반 모두: {both}")
only_a = class_a - class_b
print(f"A반에만: {only_a}")오늘의 정리
| 상황 | 추천 자료구조 |
|---|---|
| 순서대로 저장, 수정 필요 | 리스트 [ ] |
| 변경되면 안 되는 데이터 | 튜플 ( ) |
| 중복 제거, 집합 연산 | 세트 { } |
| 이름(키)으로 값 접근 | 딕셔너리 {k: v} |
| 빠른 검색 (in 연산) | 세트 또는 딕셔너리 |
다음 편 예고: 함수 (1) - 코드를 재사용하는 방법
같은 코드를 여러 번 반복해서 쓰고 있다면? 함수로 한 번 만들어두면 이름만 불러서 재사용할 수 있다. 프로그래밍의 핵심 원칙인 "반복하지 마라(DRY)"를 실천하는 방법을 알아보자.
태그: 파이썬 Python 파이썬독학 자료구조 리스트 딕셔너리 튜플 세트 성능비교 파이썬기초 IT교육
반응형
'Python' 카테고리의 다른 글
| 18. 함수 (2) - 스코프와 고급 기능 (0) | 2026.02.22 |
|---|---|
| 17. 함수 (1) - 코드를 재사용하는 방법 (0) | 2026.02.22 |
| 15. 컴프리헨션 - 파이썬다운 코드 작성법 (0) | 2026.02.22 |
| 14. 튜플과 세트 - 용도에 맞는 그릇 선택 (0) | 2026.02.22 |
| 13. 딕셔너리 - 이름표를 붙인 데이터 (0) | 2026.02.22 |




댓글